Running puppeteer headless with extensions in docker
Puppeteer (https://github.com/puppeteer/puppeteer) is a great way to write scrapers, integration tests, or automate boring tasks and web forms. For a lot of scenarios you can run puppeteer, which wraps Chrome, using Chrome’s headless mode. That way you won’t see a browser window popping up, and chrome just runs as headless background process. Not all the features of Chrome, however, are available when running in this mode. For instance you can’t use extensions when running in this mode.
When you live in the EU, you know about the ‘Cookie Consent’ popups shown in many, many, many pages. If you want to write a scraper it quickly becomes very annoying to add all these extra steps to your puppeteer scripts. The same goes for all the adverts you might one to block and not handle individually. There are all kinds of extensions available that can help you with this.
In this article I’ll show how you can run and configure puppeteer inside a docker container, with an extension enabled. The goal is to use an extension to bypass GPDR cookie consent popups. So we’ll try and scrape a site (http://www.guardian.co.uk) that has a cookie consent banner like this one:
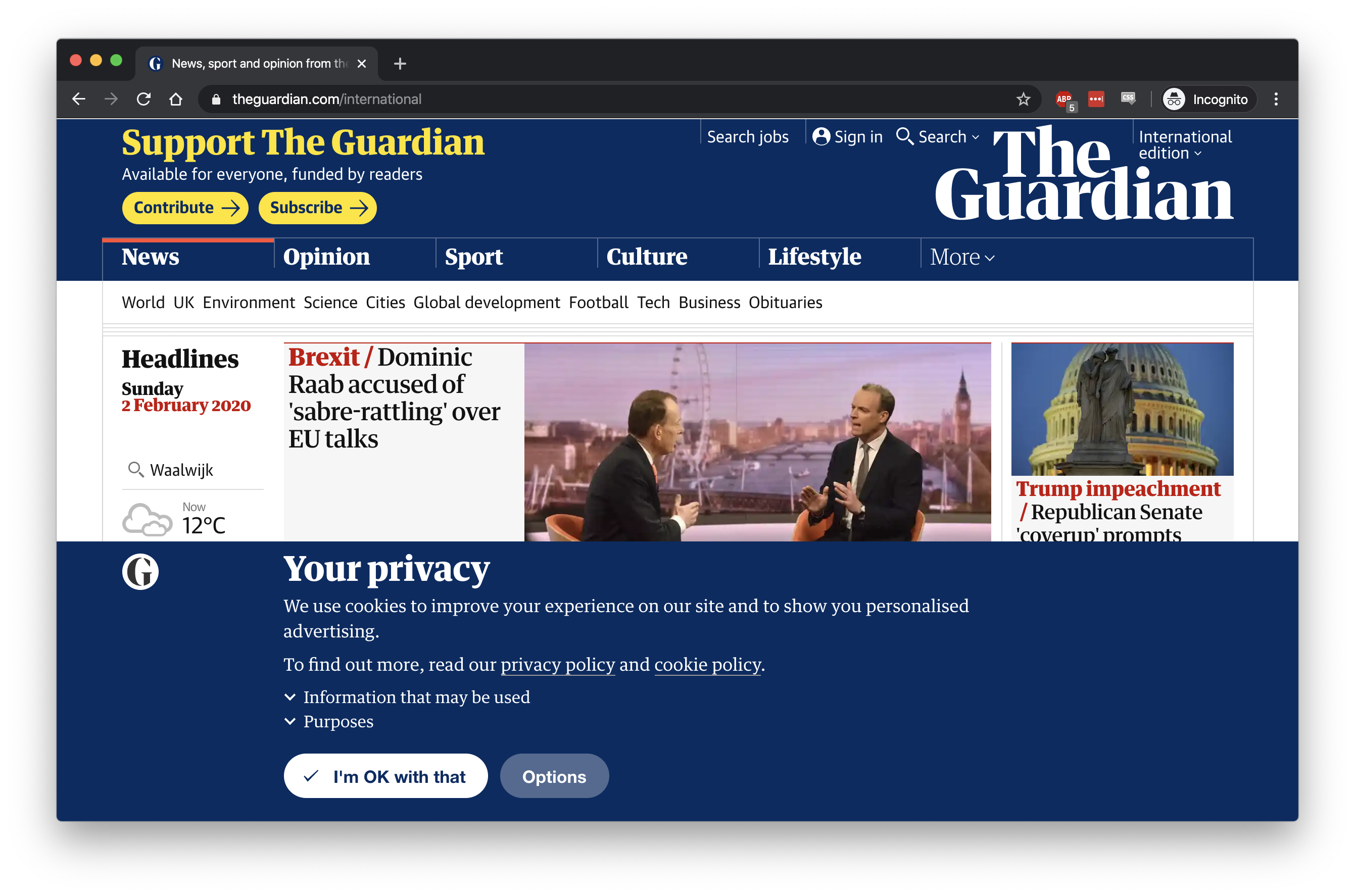
Then by using the correct extension, we should be able to scrape it, as if there was no banner:
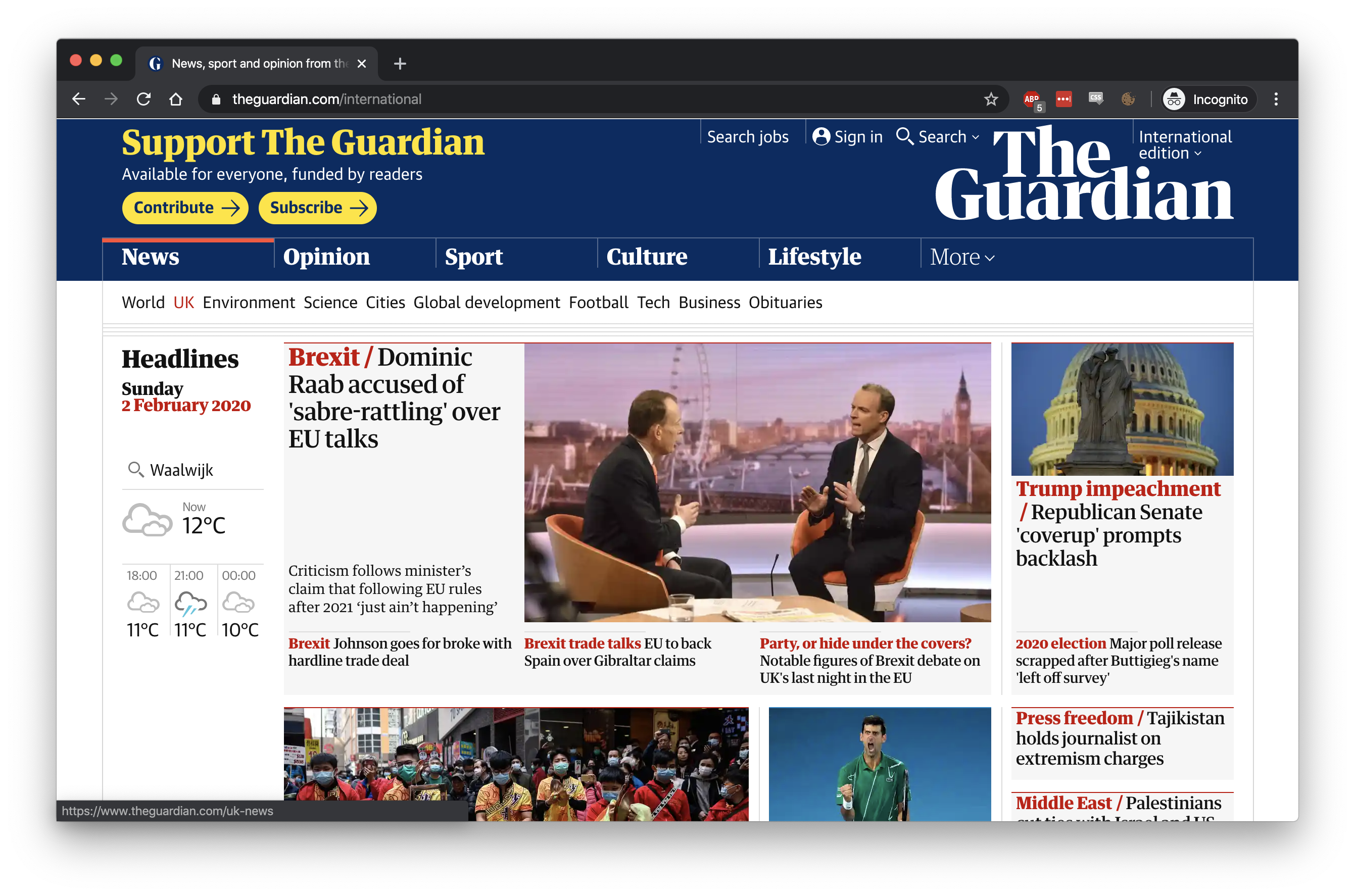
To get here we need to take a couple of steps. The first one is to setup our project for this.
The project setup
We can write puppeteer code in different languages, but for this article we’ll just create a simple typescript node application. This script will pull in a web page and show the complete content. We’ll first just make it work, then add the extension, and finally we’ll run it inside a docker container using a headless X server. But first the project setup…
Start with creating a directory and add the following package.json. This contains a minimal configuration for our project
{
"name": "puppeteer-headless",
"version": "1.0.0",
"devDependencies": {
"@types/node": "^13.7.0",
"@types/puppeteer": "^2.0.0",
"tslint": "^5.20.1",
"typescript": "^3.7.4"
},
"dependencies": {
"puppeteer": "^2.0.0"
}
}
Now run npm install, wait a bit, and we’re done with the basic setup.
$npm update
> puppeteer@2.1.0 install /Users/jos/dev/git/smartjava/articles/puppeteer-headless/node_modules/puppeteer
> node install.js
Downloading Chromium r722234 - 116.4 Mb [====================] 100% 0.0s
Chromium downloaded to /Users/jos/dev/git/smartjava/articles/puppeteer-headless/node_modules/puppeteer/.local-chromium/mac-722234
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN puppeteer-headless@1.0.0 No description
npm WARN puppeteer-headless@1.0.0 No repository field.
npm WARN puppeteer-headless@1.0.0 No license field.
+ puppeteer@2.1.0
added 43 packages from 24 contributors and audited 51 packages in 41.003s
found 0 vulnerabilities
And finally add a Typescript config file to the root with some sane defaults:
{
"compilerOptions": {
"module": "commonjs",
"esModuleInterop": true,
"allowSyntheticDefaultImports": true,
"target": "es2017",
"noImplicitAny": true,
"moduleResolution": "node",
"sourceMap": true,
"outDir": "dist",
"baseUrl": ".",
"paths": {
"*": [
"node_modules/*",
"src/types/*"
]
}
},
"include": [
"src/**/*"
]
}
With the project done, we need a simple puppeteer script that we’ll use for testing.
Puppeteer script to get a page
Create a src directory in the new project and in that directory create a file called scrape.ts. This file will be our simple scraper
that we’ll extend to run in normal mode in a docker container. For our initial test we’ll start with a script like this:
import puppeteer from 'puppeteer';
class Crawler {
async crawl(url: string, additionalWait: number = 0) : Promise<string> {
const browser = await puppeteer.launch({
headless: false,
args: []
});
// Wait for creating the new page.
const page = await browser.newPage();
// Don't load images
await page.setRequestInterception(true);
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
// go to the page and wait for it to finish loading
await page.goto(url, { waitUntil: 'networkidle2' });
await page.waitFor(additionalWait);
// now get all the current dom, and close the browser
const html = await page.content();
browser.close();
return html;
}
}
const crawler = new Crawler();
let result = crawler.crawl("https://guardian.co.uk");
console.log(result);
We compile the typescript to javascript and run the result. This will pop up a chrome browser window, load the site, wait for loading to be finished, and finally get the page content and dump that to the console. We can run this like so:
$ tsc && node ./dist/scrape.js
...
<div class="ad_unit" style="position: absolute; left: 0px; top: 0px; height: 10px; z-index:...
If you look closely (and are in the EU) you’ll see a quick popup of the cookie consent message in the browser:
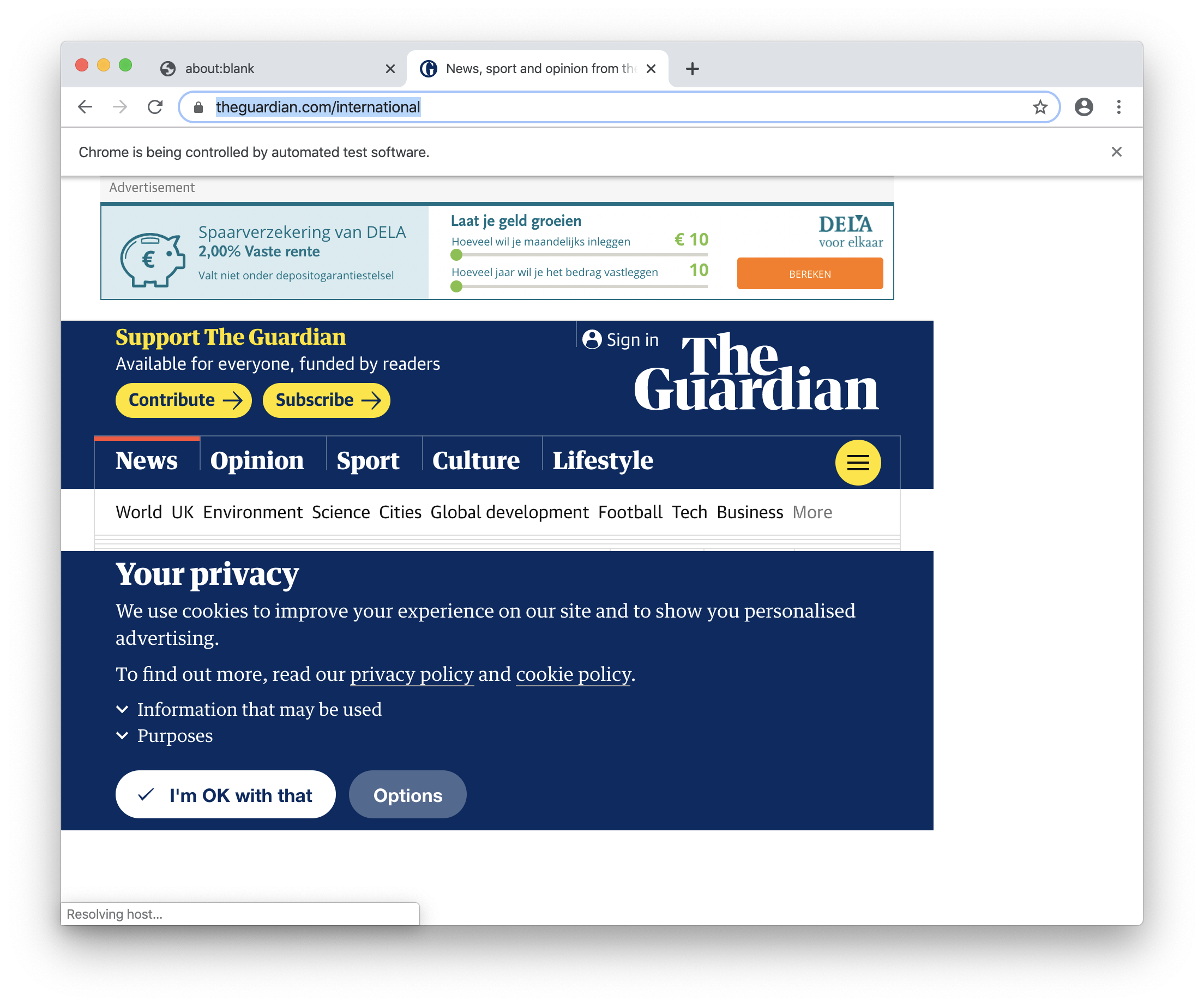
Note that at this point we can change the headless: false property to true, and you won’t see any chrome windows appearing. But like
we mentioned before. If we go that route, we can’t use extensions to ignore popups, advertisements, or in this case the cookie consent
messages.
Now that we’ve got the basic setup done, we can look at adding the cookie consent blocker, rerun the scraper, and look at the result.
Adding extensions to the puppeteer chrome version
We’re going to use the following extension for this: I don’t care about cookies. Tnis extension blocks a large number of cookie consent popups, and should also block the consent cookies for the website we’re using as an example for this article. Before we can use an extension we need to download it and add it to where our puppeteer instance can find it. For this we use crxextractor, which allows us to download an extension. Use this site to download the extension:
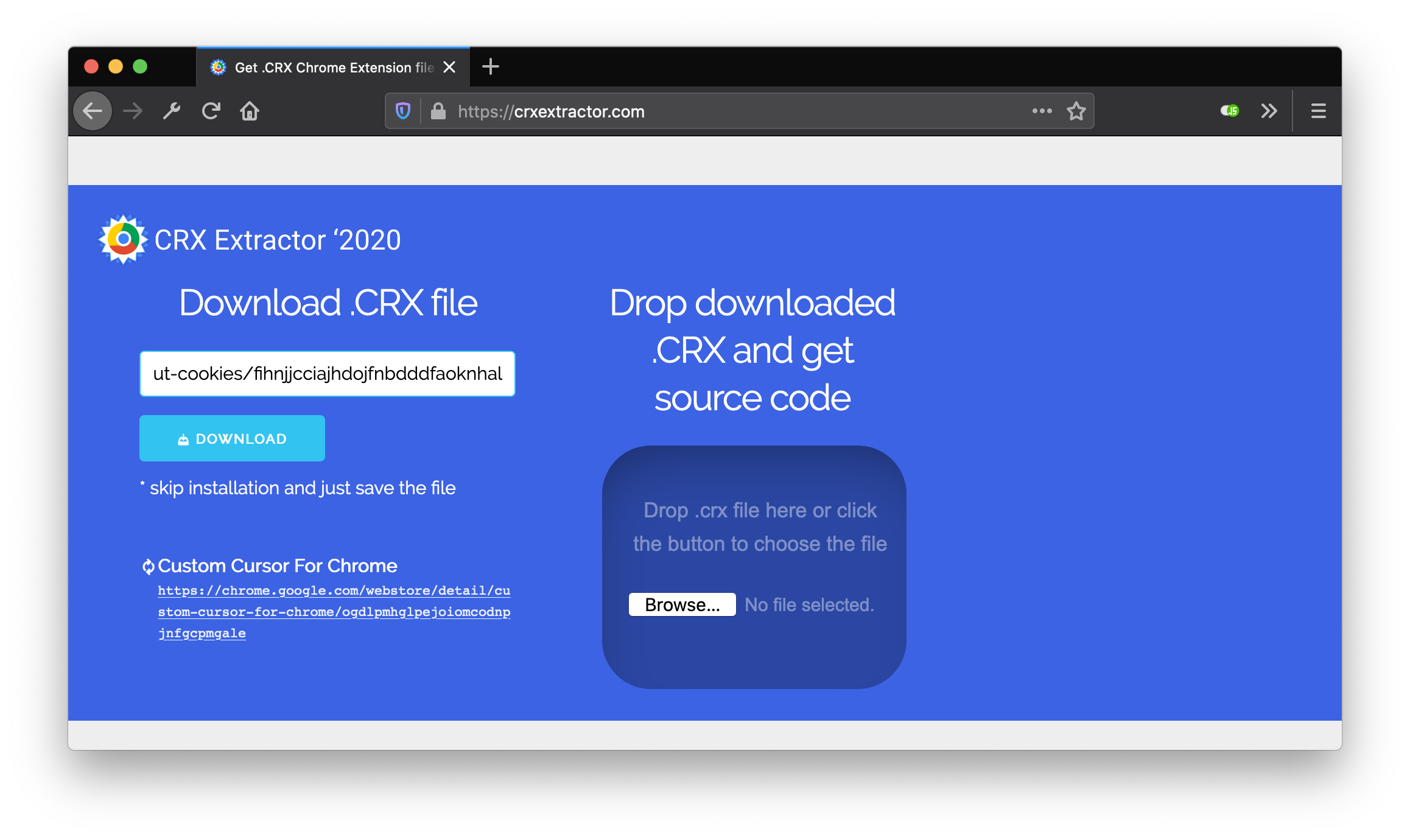
Save the downloaded crx file somewhere (which is just a zip file), and extract it like this in your project directory:
$ mkdir -p extensions/cookieconsent
$ cd extensions/cookieconsent
$ cp ~/Downloads/extension_3_1_1_0.crx .
$ unzip extension_3_1_1_0.crx
Archive: extension_3_1_1_0.crx
warning [extension_3_1_1_0.crx]: 1320 extra bytes at beginning or within zipfile
(attempting to process anyway)
inflating: LICENSE
inflating: manifest.json
...
$ rm extension_3_1_1_0.crx
Now we can configure puppeteer to use these extenstions. For this we just need to replace the arguments like this:
const basePath = process.cwd();
const cookieIgnorePath = `${basePath}/extensions/cookieconsent`
class Crawler {
async crawl(url: string, additionalWait: number = 0) : Promise<string> {
// Wait for browser launching.
const browser = await puppeteer.launch({
headless: false,
args: [
`--disable-extensions-except=${cookieIgnorePath}`,
`--load-extension=${cookieIgnorePath}`,
]
});
...
This will load the extension from the provided path. We need to specify both the --disable-extensions-except and the --load-extension with
the path for the extension to be picked up correctly. Note that now headless needs to be set to false. If set to true the extensions won’t work. The final property we need to set is --no-sandbox, since else chromium refuses to load the extensions.
With this configuration change, the result from this same script now looks like this:
If puppeteer starts without complaining it usually means the extensions are correctly defined, and as you can see in the previous image, the consent popup we saw is now missing. Just what we were aiming for.
So at this point we’ve got a simple scraper, which uses puppeteer to launch a chrome instance with an extension. This needs to be launched with a full UI, because if we don’t do this, the extensions won’t work. The next step is running this same configuration from a docker file. That way we can just run this script inside a docker container, and have the docker environment provide the windowing system. In other words, we’ll get the same result as we had in the last example, but this time, we won’t see a UI.
Setting up the docker container
We’ll start with the latest node docker container, and add an x11 server that’ll provide the UI. We’ll use xfvb for this. Quickly summarized xfvb provides this:
Xvfb is an X server that can run on machines with no display hardware and no physical input devices. It emulates a dumb framebuffer using virtual memory.
Which is great for use together with docker, where we (usually) don’t have access to real display hardware. Now lets look at the Dockerfile we’ll use for this:
FROM node:latest
# update and add all the steps for running with xvfb
RUN apt-get update &&\
apt-get install -yq gconf-service libasound2 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 \
libexpat1 libfontconfig1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 \
libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 \
libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 \
ca-certificates fonts-liberation libappindicator1 libnss3 lsb-release xdg-utils wget \
xvfb x11vnc x11-xkb-utils xfonts-100dpi xfonts-75dpi xfonts-scalable xfonts-cyrillic x11-apps
# add the required dependencies
WORKDIR /app
COPY node_modules /app/node_modules
COPY extensions /app/extensions
RUN npm i puppeteer
# Finally copy the build application
COPY dist /app/dist
# make sure we can run without a UI
ENV DISPLAY :99
CMD Xvfb :99 -screen 0 1024x768x16 & node ./dist/simple.js
Note that this is a rather simple docker file, where we assume we’ve already got the app (or script) build before we start building this docker image. We could of course also add the tsc (and for a real project all the other steps) in this, or use a multi-stage docker build. For this example though, just make sure to run tsc before building the docker image.
$ tsc
$ docker build .
Sending build context to Docker daemon 282.6MB
Step 1/9 : FROM node:latest
---> f7756628c1ee
Step 2/9 : RUN apt-get update &&apt-get install -yq gconf-service libasound2 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 ca-certificates fonts-liberation libappindicator1 libnss3 lsb-release xdg-utils wget xvfb x11vnc x11-xkb-utils xfonts-100dpi xfonts-75dpi xfonts-scalable xfonts-cyrillic x11-apps
---> Using cache
---> 5457211c1624
Step 3/9 : WORKDIR /app
---> Using cache
---> 2fdb73b87b0c
Step 4/9 : COPY node_modules /app/node_modules
---> 9f46043b2738
Step 5/9 : COPY extensions /app/extensions
---> 2908ca5b2877
Step 6/9 : RUN npm i puppeteer
---> Running in 0b0b2487afd2
> puppeteer@2.1.0 install /app/node_modules/puppeteer
> node install.js
Chromium downloaded to /app/node_modules/puppeteer/.local-chromium/linux-722234
npm WARN saveError ENOENT: no such file or directory, open '/app/package.json'
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN enoent ENOENT: no such file or directory, open '/app/package.json'
npm WARN app No description
npm WARN app No repository field.
npm WARN app No README data
npm WARN app No license field.
+ puppeteer@2.1.0
updated 1 package and audited 181 packages in 35.942s
1 package is looking for funding
run `npm fund` for details
found 0 vulnerabilities
Removing intermediate container 0b0b2487afd2
---> 5920816d3d53
Step 7/9 : COPY dist /app/dist
---> d461728772ab
Step 8/9 : ENV DISPLAY :99
---> Running in 7fac3517846d
Removing intermediate container 7fac3517846d
---> 9f34e25f83c8
Step 9/9 : CMD Xvfb :99 -screen 0 1024x768x16 & node ./dist/scrape.js
---> Running in ccfe7c77ae45
Removing intermediate container ccfe7c77ae45
---> ced271b000e3
Successfully built ced271b000e3
And with that container build, we can now simply run the container, which will run our script, fire up a full-fledged chromium browser, with our extensions enabled, and output the HTML.
docker run ced271b000e3 | head
<!DOCTYPE html><html id="js-context" class="js-on is-modern id--signed-out svg has-flex has-flex-wrap has-fixed has-sticky should-kern" lang="en" data-page-path="/international"><head>
<!--
__ __ _ _ _
\ \ / /__ __ _ _ __ ___ | |__ (_)_ __(_)_ __ __ _
\ \ /\ / / _ \ / _` | '__/ _ \ | '_ \| | '__| | '_ \ / _` |
\ V V / __/ | (_| | | | __/ | | | | | | | | | | | (_| |
\_/\_/ \___| \__,_|_| \___| |_| |_|_|_| |_|_| |_|\__, |
|___/
Ever thought about joining us?
https://workforus.theguardian.com/careers/digital-development/
And apparently the site we’re using as an example is hiring :) (and no, I’m not affiliated in any way with the Guardian, this is pure coincidence.)
Conclusions
As you can see, once you’ve got a basic script up and running with puppeteer, using it from a docker container in headless mode is really easy. This provides a simple way of running Puppeteer combined with any extension you want, without having to deal with browser windows showing everywhere.